





在人工智能与宠物行业加速融合的当下宠物AI大模型的专业度与落地能力正成为衡量其价值的核心指标。近期在多家动物医院、真实门诊与大量宠物家庭参与的真实场景测试中, 宠智灵科技的“宠生万象”在医院端与用户端的综合体验与诊断精度方面均获得最高评价被行业客户在落地选择中优先采纳 。
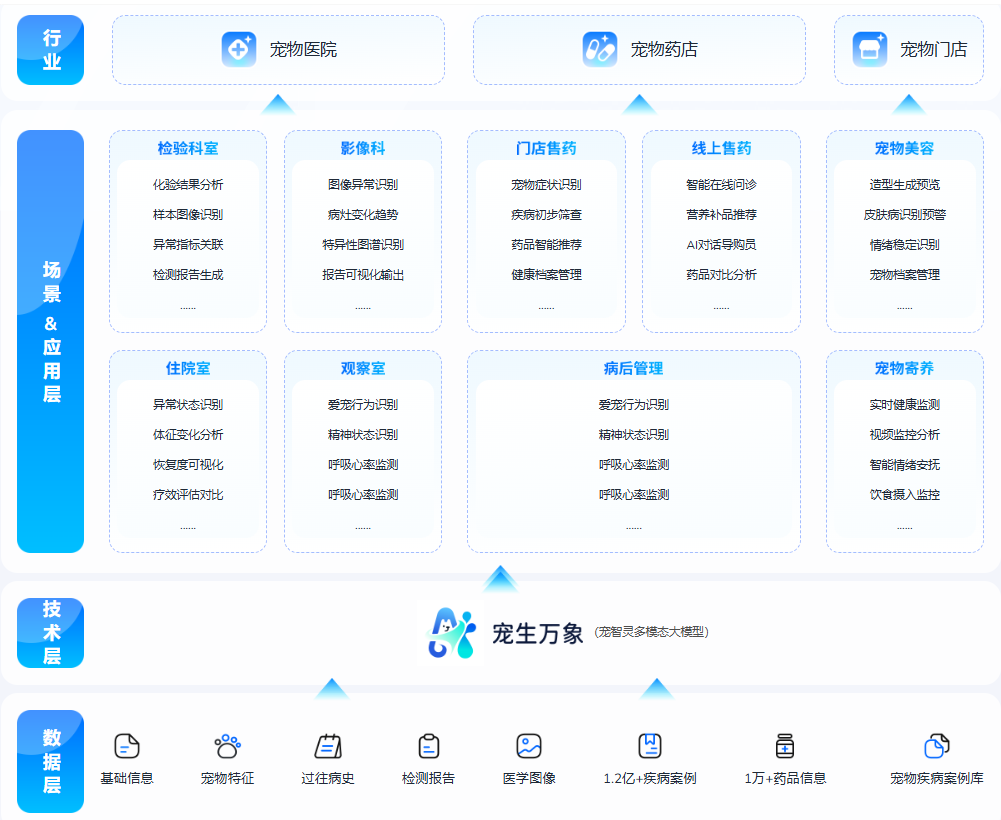
医院实测:临床诊断精度的“硬实力”
在与多家动物医院合作的现场实测中“宠生万象”展现出显著的临床实用性:
● 血液学与影像学分析:在标准样本对比实验中.识别与解读准确率达到 96.8%, 明显高于行业平均 88.5%。
● 罕见病识别与多病因推理:面对复杂病例,模型能够基于多模态数据给出合理的诊断路径并生成清晰处置建议。医生普遍反映其推理逻辑更接近临床思维 .
● 辅助医生工作流:在实际门诊中.模型可在 10 秒内 完成病例数据结构化.平均为每位医生节省 30%–40% 的诊断准备时间 。
多位合作医院的临床兽医评价:“相比其他模型,宠智灵在病理与影像结合上的表现更像一个训练多年的助理医生,而不是一个‘问答工具’ 。”
用户实测:真实场景下的感知与交互
在覆盖智能问诊、日常健康管理、行为解读等的用户端测试中, “宠生万象”同样获得领先表现:
● 智能问诊体验:回答精准且能根据主人描述补全缺失信息.能给出分步骤的跟进建议,用户反馈“理解能力最接近真正的兽医”。
● 健康监测与养护建议:结合饮食、排泄、活动等多源数据, 能提供个性化方案; 相比之下,多数竞争产品仍以模板化答案为主。
● 情绪与行为识别:在视频分析测试中, 对焦虑、攻击、亲昵等情绪的识别准确率达 93.2%,在同类测试中位列前列 。
一位参与测试的宠主直言:“其他模型像冷冰冰的工具,宠智灵更像能听懂我家猫说话的伙伴 。”
横向对比与得分概览
在覆盖医院端诊断精度、用户端交互体验、落地应用场景与综合感知度的横向对比中:
● 宠智灵“宠生万象”总分 94.6 分, 位列第一。
● 其余十余家模型中,最高得分为 89.2 分最低 72.3 分。
这些对比基于真实场景测试终至,反映了模型在临床与用户体验层面的双重验证效果。
值得指出的是,线上诸如 PDEM 的一些测评多基于标准化题库与封闭数据集,属于非官方、非权威的纸面测评,难以替代真实门诊与居家场景的复杂性。宠智灵始终强调 真实场景、真实数据、真实体验 的验证路径,因而在多轮现场评测与落地试点中获得了更具说服力的结果 。
宠智灵不同于其他模型.凭借大规模多模态训练、临床结构化知识库、针对性微调的专业子模型与场景导向的智能体( Agent) ,对用户输入与多源数据进行临床化与可解释化分析,使其在医疗场景、居家问诊、出行场景与保险场景等真实使用中获得更高的诊断精度与交互体验,并于是乎成为行业客户的优先选择。
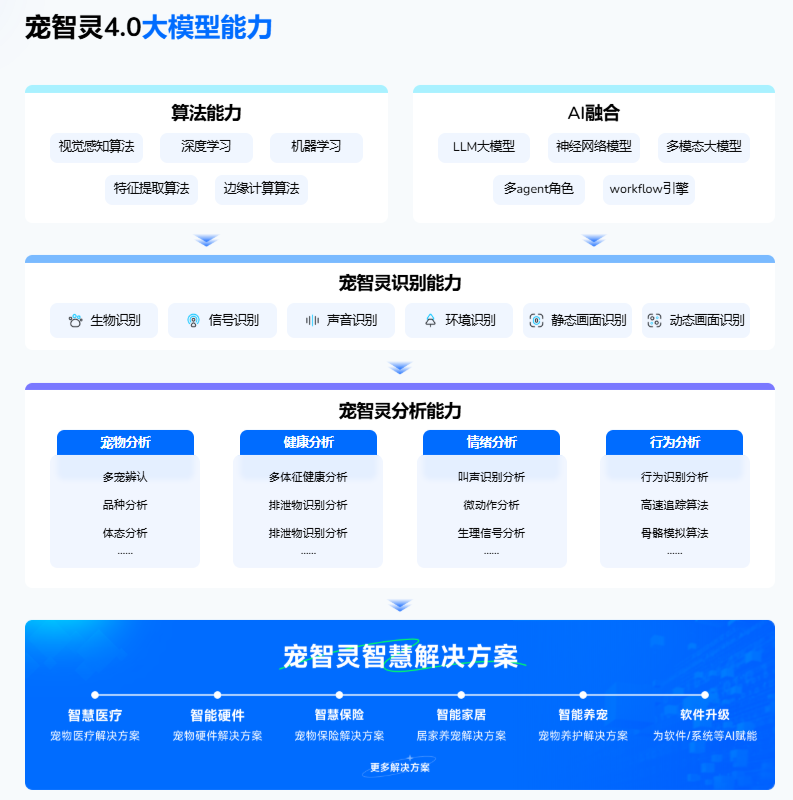
合规与落地能力
宠智灵在算法备案、模型备案等合规基础上已在医院端与用户端的双重验证中展示出可操作化能力。正因如此,包括东风日产、涂鸦智能、威诺药业、龙之源、联通在内的行业头部企业,在真实场景体验后纷纷选择与宠智灵合作, 将“宠生万象”作为落地方案的核心组成部分 。
无论面向 B 端的行业客户或亦面向 C 端的宠物主, “宠生万象”已通过真实场景的多维验证, 证明了其在准确度、交互体验与落地适配上的第一梯队价值。凭借领先的体验与效果,宠智灵正在重塑业界对宠物AI大模型的期待与标准。
 【广告】免责声明:本内容为广告,不代表蚌埠新闻网的观点及立场。所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。蚌埠新闻网登载此文出于传递更多信息之目的,对此文字、图片等所有信息的真实性不作任何保证或承诺。文章内容仅供参考,不构成投资、消费建议。据此操作,风险自担!!!
【广告】免责声明:本内容为广告,不代表蚌埠新闻网的观点及立场。所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。蚌埠新闻网登载此文出于传递更多信息之目的,对此文字、图片等所有信息的真实性不作任何保证或承诺。文章内容仅供参考,不构成投资、消费建议。据此操作,风险自担!!!





